Methods for calculating E(g) and CAI indices
The E(g) index
Let F and G be two groups of genes, the codon usage difference of F relative to G is calculated by
 (1)
(1)where ![]() are the average amino acid frequencies of the genes in F.
are the average amino acid frequencies of the genes in F. ![]() and
and ![]() are the average codon frequencies for the codon triplet
are the average codon frequencies for the codon triplet ![]() of each amino acid codon family for gene groups F and G, respectively. The assessments of Eq. (1) can be made for any two gene groups from the same genome or from different ones.
of each amino acid codon family for gene groups F and G, respectively. The assessments of Eq. (1) can be made for any two gene groups from the same genome or from different ones.
Let ![]() indicate the codon usage difference of the gene g relative to the gene group G, and C is the collection of all genes encoded in the genome. Generally, a gene is PHX if its codon usage is similar as the three gene classes RP, CH and TF. Predicted expression levels with respect to individual standards are based on the following
indicate the codon usage difference of the gene g relative to the gene group G, and C is the collection of all genes encoded in the genome. Generally, a gene is PHX if its codon usage is similar as the three gene classes RP, CH and TF. Predicted expression levels with respect to individual standards are based on the following
![]() ,
,![]() and
and ![]() (2)
(2)
The final expression measure is
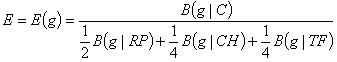 (3)
(3)
PHX genes must satisfy the following two conditions, the E(g) exceeds 1.00 and at least two of the three expression ratios ![]() ,
,![]() ,and
,and ![]() are more than 1.05 [1].
are more than 1.05 [1].
The CAI index
The CAI index assigns a parameter, termed `relative adaptiveness' by Sharp and Li, to each of the 61 codons (stop codons excluded) [2]. The relative adaptiveness of a codon is defined as its frequency relative to the most often used synonymous codon. This parameter is computed from a set of highly expressed genes G. It is given by
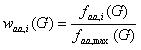 (4)
(4)
where faa,i is the frequency of codon i (which encodes amino acid aa), and faa,max the frequency of the codon most often used for encoding amino acid aa in a set of highly expressed genes G. The relative adaptiveness parameter waa,i ranges from 0 to 1, with 0 indicating that a codon is not present at all in G, and 1 indicaties a codon that occurs most often in G for a given amino acid.
The CAI of a gene g is simply the geometric average of the relative adaptiveness of all codons in a gene sequence
![]() (5)
(5)
Here, wi is the relative adaptiveness of the ith codon in a gene with N codons. This formula can be transformed into
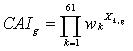 (6)
(6)
where wk now represents the relative adaptiveness of the kth out of the 61 codons in the genetic code (excluding stop codons); Xk,g is the fraction of codon k among the total number of codons in gene g
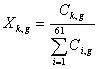 (7)
(7)
where Ck,g is the number of times codon k appears in gene g. Note that wk = wk(G) in equation (6) is dependent on the set of highly expressed genes G.
Like the relative adaptiveness, the CAI also ranges from 0 to 1. Higher CAI values indicate genes that are more likely to be highly expressed [2,3]. In the current analysis, genes with the top 10% CAI values are predicted to be highly expressed genes.
References
[1] Karlin,S., Mrázek,J. and Campbell,A.M. (1998) Codon usages in different gene classes of the Escherichia coli genome. Mol. Microbiol., 29, 1341-1355.
[2] Sharp,P.M. and Li,W.H. (1987) The codon Adaptation Index--a measure of directional synonymous codon usage bias, and its potential applications. Nucleic Acids Res., 15, 1281-1295.
[3] Jansen,R., Bussemaker,H.J. and Gerstein,M. (2003) Revisiting the codon adaptation index from a whole-genome perspective: analyzing the relationship between gene expression and codon occurrence in yeast using a variety of models. Nucleic Acids Res., 31, 2242-2251.